
I am a Ph.D. student at the University of Hong Kong (HKU-MMLab) (Sep. 2025 - .), where Prof. Xihui Liu is my advisor.
Previously, I spent a wonderful year working on generalist robotics as a full-time researcher with Dr. Tao Kong at ByteDance Research (Seed-Robotics) (Jul. 2024 - Aug. 2025). I received my Master’s degree from Fudan University (Sep. 2021 - Jun. 2024), where Prof. Tao Chen is my advisor. I am fortunate to work closely with Dr. Hongyuan Zhu from A*STAR, Singapore, and Dr. Gang Yu, Dr. Xin Chen, and Dr. Chi Zhang from Tencent. Before this, I obtained my Bachelor’s degree also from Fudan University (Sep. 2017 - Jun. 2021).
I am broadly interested in scalable training methods, and my work spans generalist embodied systems, generative models, and multi-modality. My long-term research goal is to develop scalable, robust and generalized multi-modality systems that can understand, generate, and interact with the physical world. Outside my research, I love sports and music.
🔥 News
- Jun. 2026. 🤖🤖 We release Translation as a Bridging Action, transferring manipulation skills from human data to bi-manual robots via a shared translation-based bridging action!
- Jun. 2026. 📣📣 We are hosting the ScaleBot Workshop, the first workshop on Scalable Robot Learning Systems at CVPR 2026, feel free to reach out!
- Feb. 2026. 🎉🎉 OmniLottie
is accepted to CVPR 2026!
- Oct. 2025. 🤖🤖 I joined ByteDance Seed (Seed-Robotics) as a Top-Seed Research Intern, working on generalist robotics.
- Sep. 2025. 🎓🎓 I started my Ph.D. at the University of Hong Kong (HKU-MMLab) with Prof. Xihui Liu.
- Jul. 2025. 🤖🤖 We release our latest Vision-Language-Action model, GR-3[demos]!
- Apr. 2025. 🎉🎉 We release OmniSVG
, a family of VLMs that generate SVGs. Accepted to NeurIPS 2025!
- Sep. 2024. 🎉🎉 Two papers accepted to NeurIPS 2024, one focuses on foundational 3D generative models (MeshXL
), and another one explores Mamba architecture for 3D detection (3DET-Mamba).
- Jul. 2024. 🎉🎉 I joined ByteDance Research as a full-time researcher, working on generalist robotics.
- May. 2024. 🎉🎉 We release MeshXL
- May. 2024. 🎉🎉 I successfully defended my master’s thesis! [defense slides]
- Apr. 2024. 🎉🎉 Vote2Cap-DETR++
is accepted to T-PAMI 2024.
- Feb. 2024. 🎉🎉 Our Large Language 3D Assistant, LL3DA
, is accepted to CVPR 2024.
- Jan. 2024. 🐧🐧 I joined Tencent as a research intern, working on 3D generation.
- Oct. 2023. 🥇🥇 Win the Scan2Cap Challenge at ICCV 2023.
- Feb. 2023. 🎉🎉 Our Vote2Cap-DETR
📈 Citations
Citation data is temporarily unavailable.
📝 Selected Publications
I am broadly interested in using language as a medium for understanding, generating, and interacting with the physical world. My research builds models that can understand (Vote2Cap-DETR, LL3DA), generate (MeshXL, OmniSVG), and interact (GR-3, Bridging Action) with the physical world. Please find my full publication list at google scholar.
(*: equal contribution, †: project lead, ‡: corresponding author)
Translation as a Bridging Action: Transferring Manipulation Skills from Humans to Robots
Preprint 2026
Sijin Chen$^{\star}$, Kaixuan Jiang$^{\star}$, Haixin Shi$^{\ddagger}$, Yanhui Wang, Weiheng Zhong, Haosheng Li, Bo Jiang, Yuxiao Liu, Xihui Liu$^{\ddagger}$
project | arXiv | huggingface
- Propose the bridging action: relative wrist translation under the head camera, a shared action space that transfers manipulation priors from humans to robots.
- A unified action space with interleaved action tokens elegantly handles the potential absence of action components across different data sources.
- Effective and scalable human-to-robot transfer that can benefit from large-scale human-only pre-training.
GR-3 Technical Report
Tech Report | Alphabetical Order
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, Hao Niu, Wenxuan Ou, Wanli Peng, Zeyu Ren, Haixin Shi, Jiawen Tian, Hongtao Wu, Xin Xiao, Yuyang Xiao, Jiafeng Xu, Yichu Yang
{kind=link}
- GR-3 follows instructions and generalizes to novel objects and concepts.
- We can adapt GR-3 to novel settings with few-shot human trajectories.
- GR-3 is able to proceed long-horizon and dexterous manipulation tasks.
- I am in charge of the multi-modal and cross-embodiment co-training.
- 🎉 Please also see our FALCON, a VLA model with robust 3D spatial perception grounded in spatial foundation priors, accepted to ICLR 2026.
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
CVPR 2026 |
Yiying Yang, Wei Cheng$^{\dagger}$, Sijin Chen, Honghao Fu, Xianfang Zeng, Yujun Cai, Gang Yu$^{\ddagger}$, Xingjun Ma
project | arXiv | github | demo
- OmniLottie generates editable, resolution-independent vector animations in Lottie JSON from interleaved text, image, and video instructions.
- A dedicated Lottie tokenizer flattens hierarchical JSON into structured function-call tokens, enabling stable and controllable generation via next-token prediction.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
NeurIPS 2025 |
Yiying Yang$^\star$, Wei Cheng$^\star$, Sijin Chen, Xianfang Zeng, Jiaxu Zhang, Liao Wang, Gang Yu, Xinjun Ma, Yu-Gang Jiang
project | arXiv | github | huggingface
- OmniSVG progressively generates SVGs spanning from simple icons to intricate anime characters.
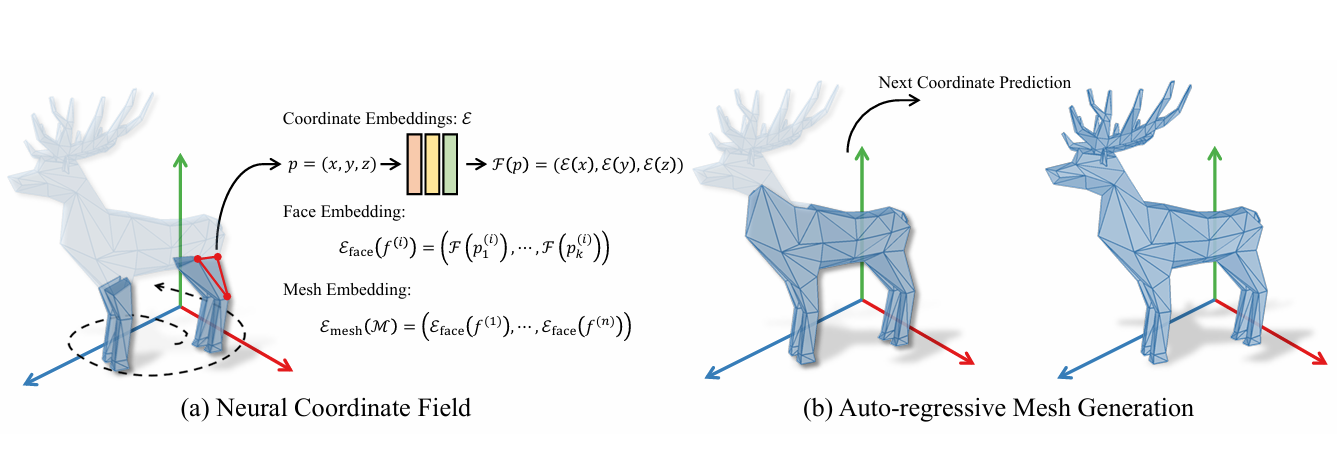
MeshXL: Neural Coordinate Field for Generative 3D Foundation Models
NeurIPS 2024 |
Sijin Chen, Xin Chen$^{\dagger}$, Anqi Pang, Xianfang Zeng, Wei Cheng, Yijun Fu, Fukun Yin, Yanru Wang, Zhibin Wang, Chi Zhang, Jingyi Yu, Gang Yu, Bin Fu, Tao Chen$^{\ddagger}$
- MeshXL turns a 3D mesh into one unique coordinate sequence, facilitating an end-to-end training pipeline for large-scale 3D mesh data.
- 🎉 Please also see our MeshAnything
, a model that mimics human artists in extracting meshes from any 3D representation, which is accepted to ICLR 2025
LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning
CVPR 2024 |
Sijin Chen, Xin Chen$^{\dagger}$, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, Tao Chen$^{\ddagger}$
paper | project | arXiv | github | youtube
- Propose a Large Language 3D Assistant that responds to both visual interactions and textual instructions in complex 3D environments.
- 🎉 Please also see our M3DBench
, a dataset querying 3D language models with multi-modal prompts. Accepted to ECCV 2024.
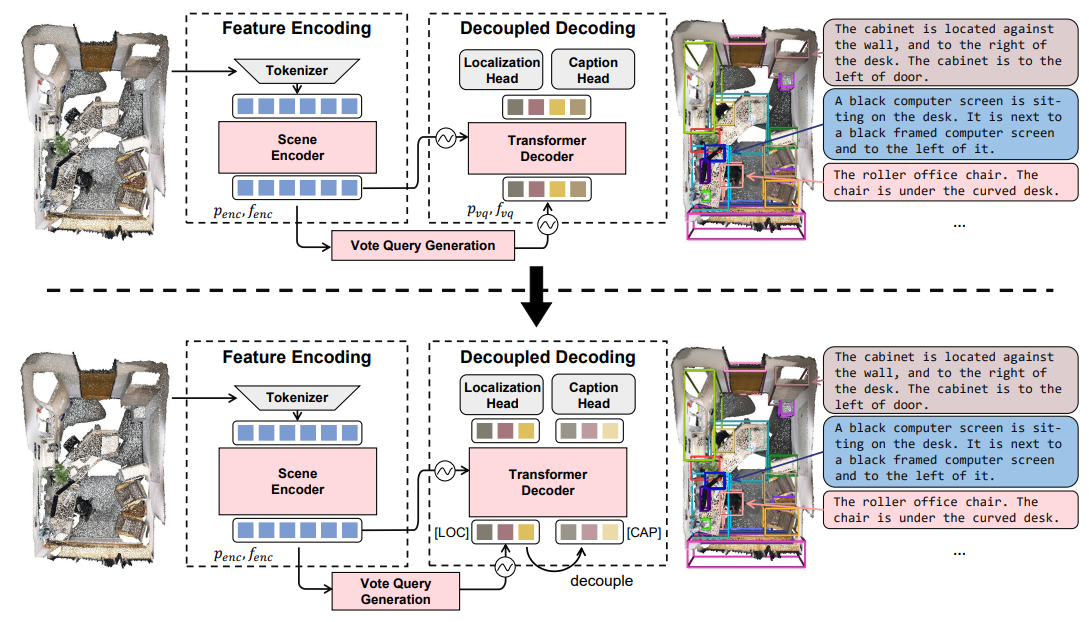
Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
T-PAMI 2024 |
Sijin Chen, Hongyuan Zhu, Mingsheng Li, Xin Chen, Peng Guo, Yinjie Lei, Gang Yu, Taihao Li, Tao Chen$^{\dagger}$
- Decoupled localization and captioning feature extraction with parallel task decoding for 3D Dense Captioning.
- 🥇 Winner of the Scan2Cap Challenge in the 3rd Language for 3D Scene Workshop at ICCV 2023. [talk]
- My preliminary paper, Vote2Cap-DETR
🥇 Awards and Scholarships
- Apr. 2025. Spot Bonus at ByteDance AI-Lab-Research (Breakthrough in new fields, 2025-Q1), comes with a trophie😮.
- Apr. 2024. Award for Outstanding Graduate Student (rank 1/24).
- Oct. 2023. 1st place of the Scan2Cap Challenge in the 3rd Language for 3D Scene Workshop at ICCV 2023.
- Sep. 2023. National Scholarship (rank 1/46).
- Sep. 2022. 2nd prize of the Scholarship for Outstanding Students of Master’s Degrees.
- Sep. 2021. Award for the Scholarship for Outstanding Students of Master’s Degrees.
- Jun. 2021. 2nd prize of the Scholarship for Outstanding Students.
{kind=link}
📖 Educations
- Sep. 2025 - .. Ph.D. student at the University of Hong Kong.
- Sep. 2021 - Jun. 2024. Master student at Fudan University.
- Sep. 2017 - Jun. 2021. Bachelor student at Fudan University.
💬 Oral Presentations
-
Jul. 2024. “MeshXL: Neural Coordinate Field for Generative 3D Foundation Models”. MeshXL paves the way for scaling up training on large-scale 3D mesh data. Our mesh representation turns a 3D mesh into one unique coordinate sequence, which enables us to simplify our architecture design into a decoder-only transformer model, facilitating an end-to-end training pipeline for large-scale 3D mesh data. Technical reports at miHoYo and AnySyn3D.
-
Oct. 2023. “Vote2Cap-DETR: A Set-to-Set Perspective Towards 3D Dense Captioning”. By treating 3D Dense Captioning as a translation task from a set of object queries into a set of ``box-caption’’ pairs, we present a set-to-set perspective towards 3D Dense Captioning. A winner presentation for the Scan2Cap challenge at ICCV 2023. [talk | slides]
-
Jun. 2023. “End-to-End 3D Dense Captioning with Vote2Cap-DETR”. We present an end-to-end transformer model for localizing and describing objects in parallel within diverse 3D environments. A paper presentation at VALSE 2023, Wuxi, China.
🧑🏫 Academic Events

ScaleBot: The First Workshop on Scalable Robot Learning Systems
CVPR 2026 Workshop | website
Sijin Chen, Shenyuan Gao, Yang Gao, Yingdong Hu, Xihui Liu, Yuxiang Lu, Philip Torr, Jianfei Yang, Zhenfei Yin, Hengshuang Zhao, Yuke Zhu.
Primary organizer. We hope to elicit discussions covering scalable data collection, training recipes, model architectures, system integration, and evaluation of general-purpose robots.
Invited speakers:
- Sergey Levine (UCB & Physical Intelligence),
- Jason Ma (Dyna-Robotics),
- Wayne Wu (UCLA), and
- Chuan Wen (SJTU).
🧑🎓 Mentorship
- Mingsheng Li (researcher @ Alibaba Qwen) — M3DBench, 3DET-Mamba, and WI3D (2022 - 2024).
- Yiying Yang (Ph.D. @ Fudan University) — OmniSVG and OmniLottie (2024 - .).
- Yue Su (incoming Ph.D. @ University of Hong Kong) — DSPv2 (2024 - .).
- Zhengshen Zhang (Ph.D. @ National University of Singapore) — FALCON (2024 - .).
🛎 Academic Services
- Workshop Organizer: primary organizer of the ScaleBot Workshop at CVPR 2026.
- Conference Reviewer: CVPR 2026, NeurIPS (2024, 2025), ICCV 2025, ICLR 2025, ICML (2025, 2026).
- Journal Reviewer: IJCV.